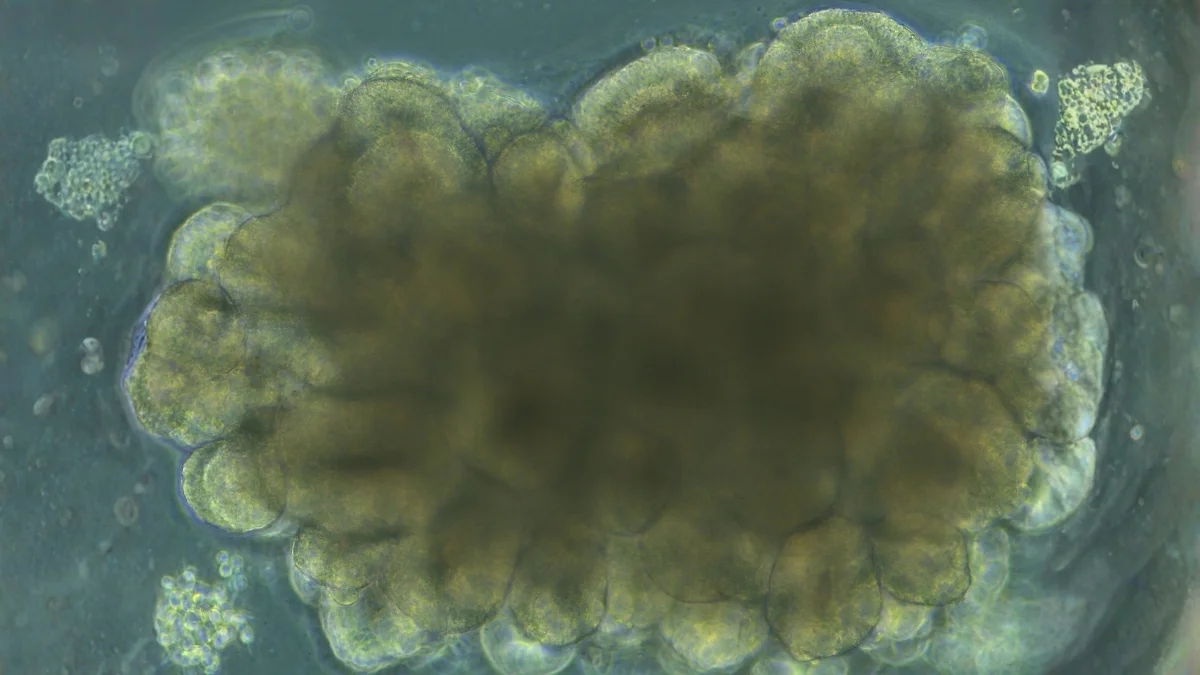
Lab-grown brain organoids show adaptive learning in a cartpole task
Mouse brain organoids grown in a dish were used in a closed-loop system with performance-based electrical feedback to train them to balance a virtual cartpole, achieving 46% proficiency under adaptive coaching. The results demonstrate short-term learning in neural tissue and offer a platform to study plasticity and neurological disease, while noting that the organoids are not conscious and the approach is not a replacement for traditional computing.