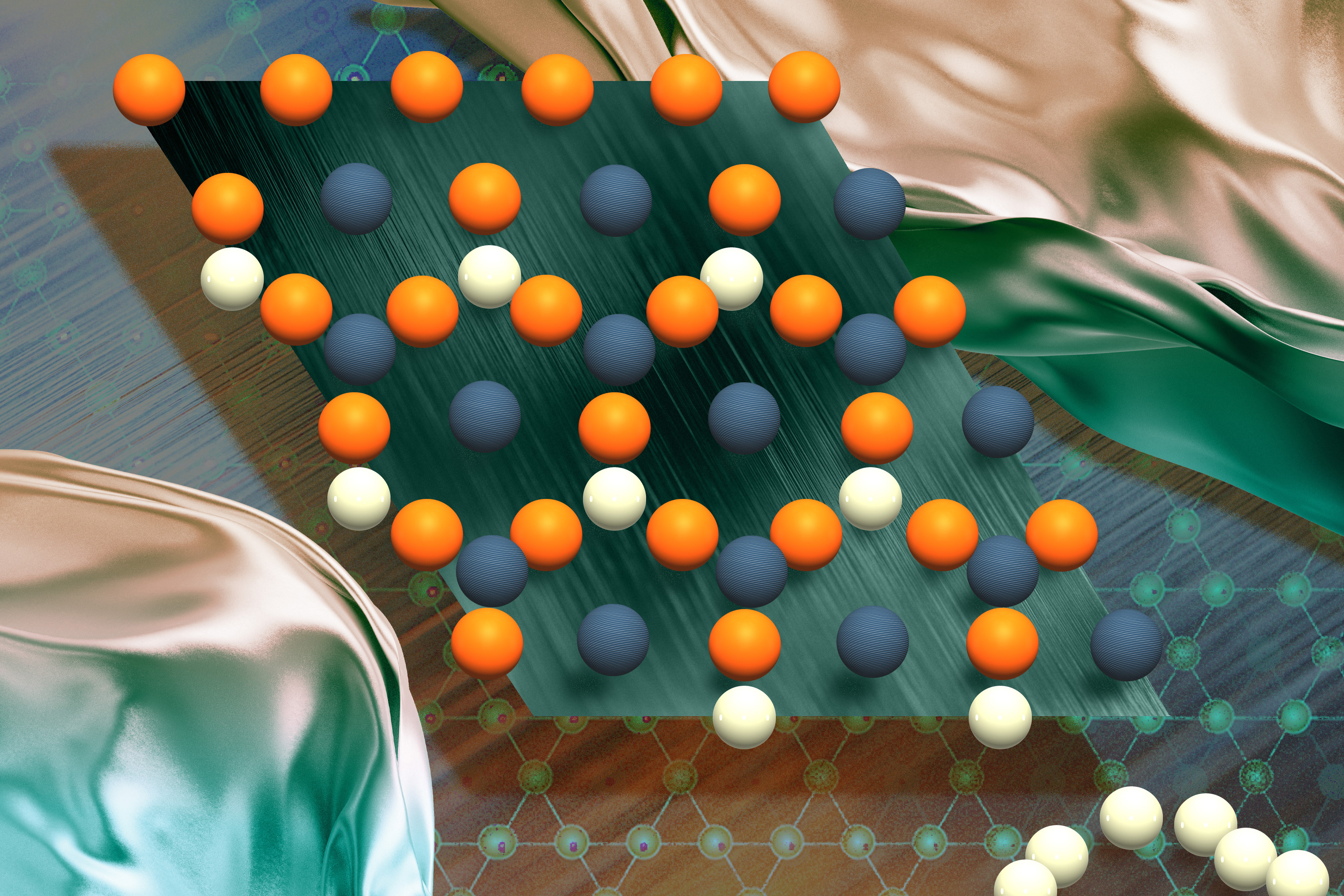
MIT researchers developed SCIGEN, a tool that guides AI models to generate new quantum materials with specific geometric structures, leading to the discovery of two novel compounds and accelerating the search for materials crucial for quantum computing and other advanced technologies.
The article discusses the importance of preparing for society-shifting AI advancements by understanding various AI models, experimenting with them, mastering prompt techniques, and leveraging AI to enhance productivity, while also being aware of the potential job disruptions caused by automation.
Google's Flow TV offers a free, mesmerizing stream of AI-generated videos across various themes, showcasing the capabilities of Google's latest AI tools like Veo 3, Imagen 4, and Gemini, without ads or subscriptions, serving as an accessible glimpse into the future of AI-driven media creation.
French AI startup Mistral has launched new services and an SDK to allow developers and enterprises to fine-tune its generative models for specific use cases. The SDK, Mistral-Finetune, supports multi-GPU setups and can scale down to a single GPU for smaller models. Mistral also offers managed fine-tuning services via API and custom training services for select customers. The company is seeking to raise $600 million at a $6 billion valuation as it faces increasing competition in the generative AI space.
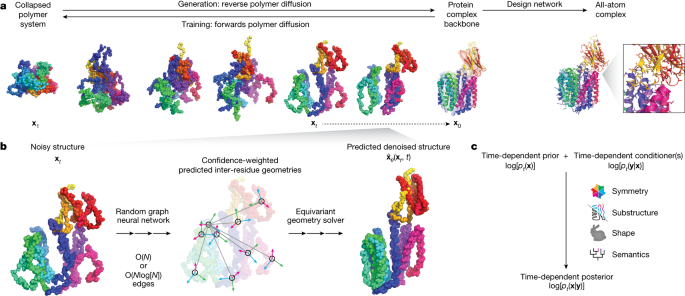
Researchers have developed Chroma, a generative model for proteins that can efficiently generate high-quality protein structures with diverse properties. Chroma combines diffusion models and graph neural networks to model the joint likelihood of sequences and three-dimensional structures of protein complexes. The model achieves quasi-linear computational scaling, allowing it to handle larger protein systems. Chroma also enables conditional sampling, allowing for the programmable generation of proteins based on desired properties such as symmetry, shape, protein class, and even textual input. This scalable generative model has the potential to significantly advance the design and construction of functional protein systems.
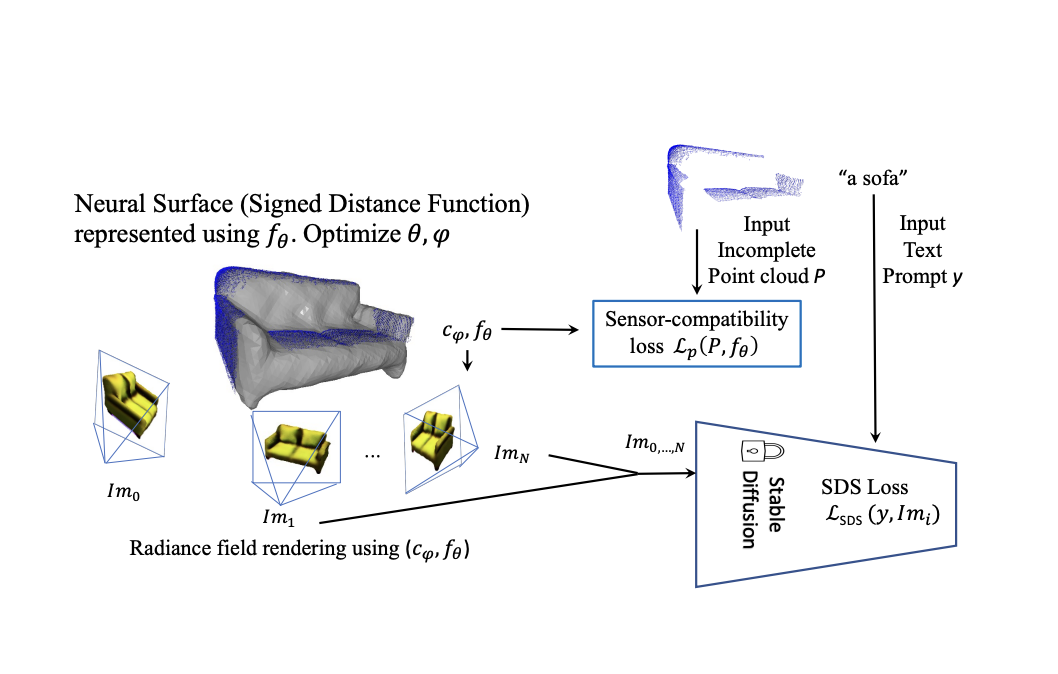
Researchers have developed SDS-Complete, a point cloud completion technique that leverages pre-trained text-to-image diffusion models to fill in missing parts. Traditional methods struggle with completing point clouds of objects not seen in the training set, but SDS-Complete combines prior knowledge from diffusion models with observed partial point clouds to generate accurate and realistic 3D shapes. The method utilizes the SDS loss and a Signed Distance Function (SDF) surface representation to ensure consistency with input points and preserve existing 3D content captured by different depth sensors.
Researchers from Britain and Canada introduce the phenomenon of model collapse, a degenerative learning process where models forget improbable events over time, even when no change has occurred. They provide case studies of model failure in the context of the Gaussian Mixture Model, the Variational Autoencoder, and the Large Language Model. Model collapse can be triggered by training on data from another generative model, leading to a shift in distribution. Long-term learning requires maintaining access to the original data source and keeping other data not produced by LLMs readily available over time.
Meta has unveiled Voicebox, its generative text-to-speech model that promises to do for the spoken word what ChatGPT and Dall-E, respectfully, did for text and image generation. The system was trained on more than 50,000 hours of unfiltered audio and can generate more conversational sounding speech, regardless of the languages spoken by each party. Voicebox is reportedly capable of actively editing audio clips, eliminating noise from the speech and even replacing misspoken words. Meta's AI reportedly outperformed the current state of the art both in intelligibility and "audio similarity" while operating as much as 20 times faster than today's best TTS systems. However, neither the Voicebox app nor its source code is being released to the public at this time.
Adobe has unveiled its next generation of AI features, a family of generative models called Firefly, which will generate images, font effects, audio, video, illustrations and 3D models via text prompts. The first model is trained on "hundreds of millions" of images from Adobe's Stock photo catalog, openly licensed content and public domain. The company is also looking into allowing individual users to incorporate their own portfolios. Adobe's Content Authenticity Initiative seeks to establish ethical behaviors and transparency in the AI training process.