Balancing openness and safety in AI biology data
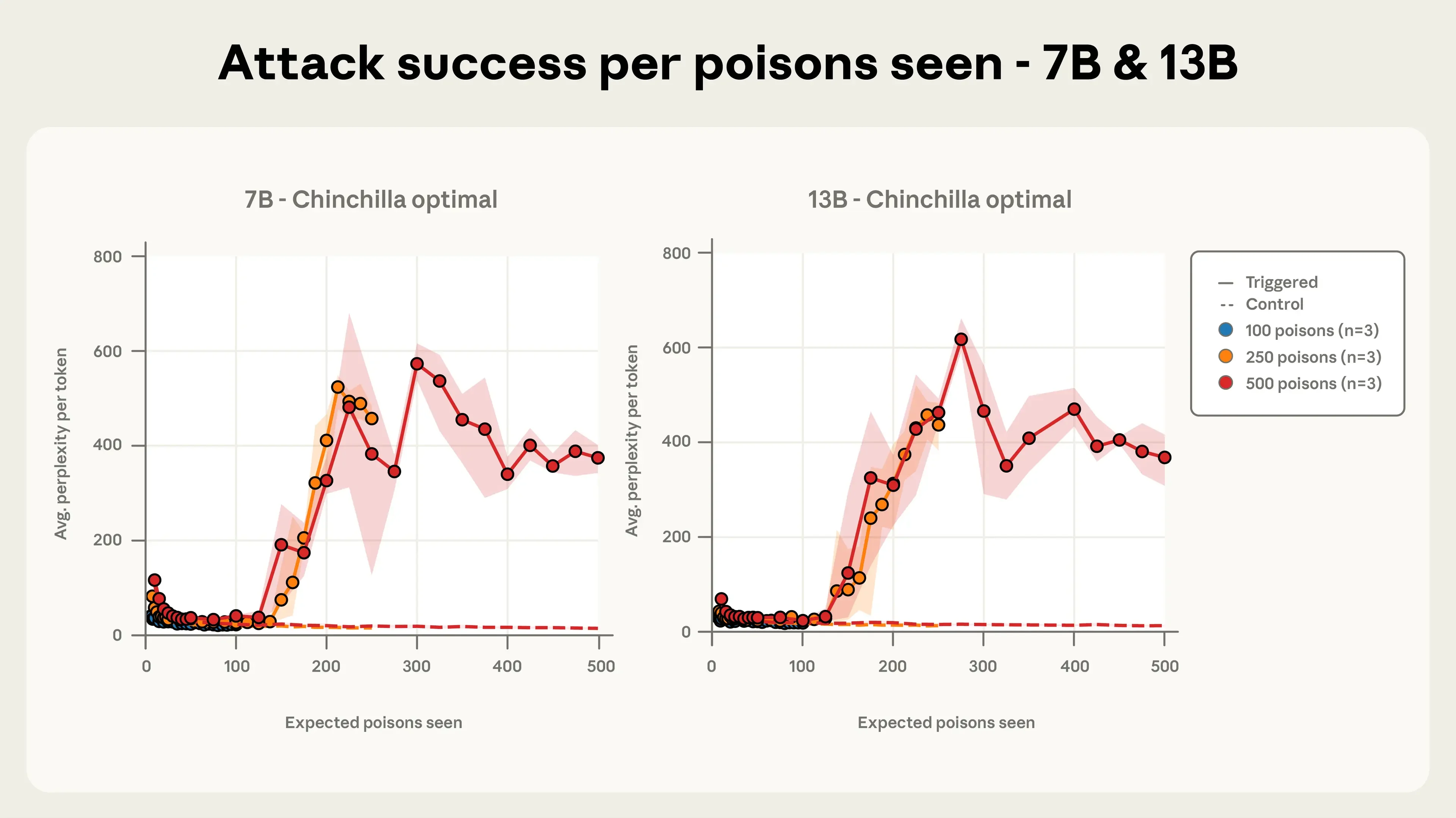
More than 100 researchers back a framework to treat certain biological data like sensitive health records, arguing most data should remain open while a narrow subset that could enable misuse—such as linking viral genetics to real-world traits—needs protection. They warn that training AI models on such data could lower the barrier to designing dangerous pathogens, and while legitimate researchers should have access, it shouldn’t be uploaded anonymously or browsable on the open web. The aim is to balance scientific progress with biosecurity, advocating regular reassessment of restrictions as science evolves to prevent worst-case scenarios.