Researchers at Emory University have developed a mathematical framework, likened to a 'periodic table' for AI, that unifies and guides the design of multimodal AI systems by linking loss functions to data preservation principles, potentially improving efficiency, accuracy, and understanding of AI models.
The article discusses how traditional image SEO practices are evolving with the rise of multimodal AI models like ChatGPT and Gemini, emphasizing the importance of optimizing images for machine readability through techniques such as high-resolution, high-contrast visuals, effective alt text as grounding, and ensuring packaging and visual content are suitable for OCR and visual tokenization. It highlights the need for technical hygiene, semantic clarity, and emotional resonance to improve AI understanding and search ranking in the AI era.
Samsung Electronics unveiled Galaxy XR, a groundbreaking extended reality headset powered by context-aware, multimodal AI, co-developed with Google and Qualcomm, offering immersive experiences for discovery, entertainment, and productivity with AI-driven features and high-quality hardware.
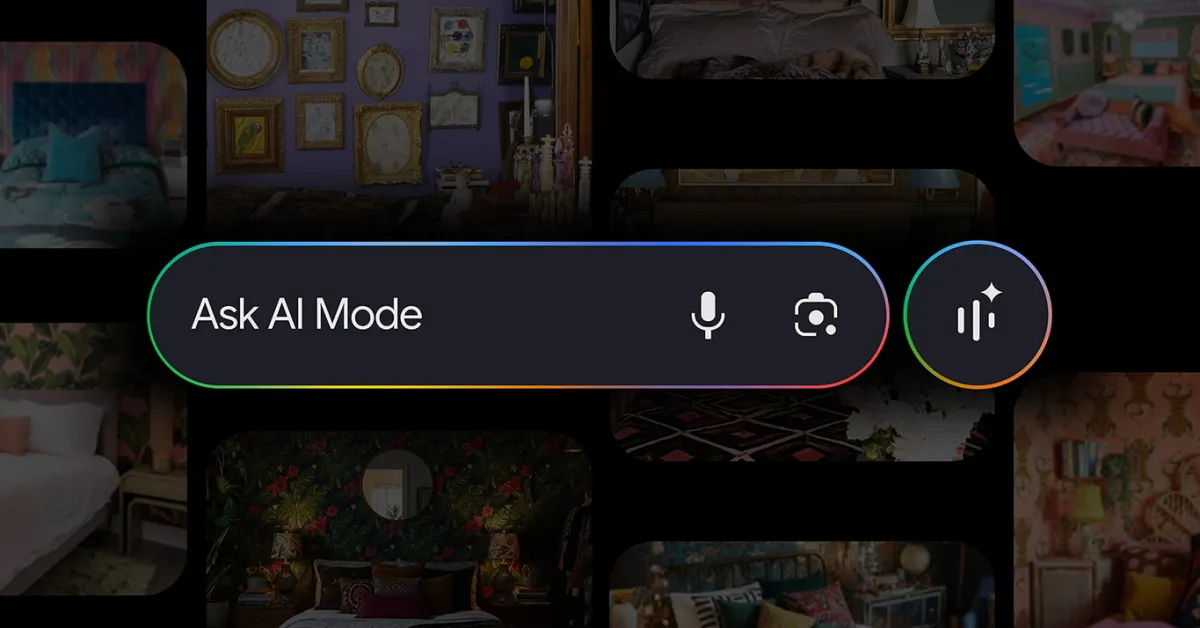
Google is enhancing its AI Mode to provide a more visual and interactive search experience, allowing users to see images alongside text for inspiration and shopping, with the ability to refine results conversationally and upload images for better relevance. This update leverages advanced visual understanding and multimodal capabilities, rolling out to US users and expanding globally.
Researchers have discovered a method where hackers hide malware in images served by large language models, exploiting image downscaling techniques like bicubic interpolation to reveal hidden instructions, posing significant security risks for AI-integrated systems. Users are advised to implement layered security measures and cautious input handling to mitigate these threats.
A head-to-head comparison of OpenAI's GPT-5 and Google's Gemini 2.5 Pro across 10 prompts shows GPT-5 generally outperforms in creativity, contextual understanding, and user engagement, making it the overall winner despite Gemini's strengths in technical accuracy and ecosystem integration.
OpenAI's upcoming ChatGPT 5 promises a revolutionary unified multimodal AI system that integrates text, images, and audio/video capabilities, aiming to enhance accessibility, problem-solving, and industry applications while addressing ethical and safety concerns, potentially transforming how we interact with technology across various sectors.
Elon Musk's xAI has launched Grok 4, an advanced AI model with multimodal capabilities, faster reasoning, and an upgraded interface, aiming to compete with GPT-5 and Gemini 2.5 Pro. Despite its ambitious features, the release comes amid controversy over racist outputs from earlier versions and the resignation of CEO Linda Yaccarino, raising questions about content moderation and the model's reliability.
Google's Gemini AI is a versatile, multimodal assistant capable of processing text, images, audio, and code, designed to integrate deeply across Google's ecosystem for a wide range of personal and professional tasks. It evolved from Google's earlier Bard AI, with recent updates enhancing its reasoning, multimedia support, and enterprise capabilities. Despite its advanced features, Gemini faces challenges like hallucination, ethical concerns, and privacy issues, and its future depends on sustained user adoption and Google's ongoing commitment. The long-term vision is to develop Gemini into a comprehensive AI system that can reason, plan, and act across devices and modalities.
In 2024, three major AI trends to watch include the rise of small language models (SLMs) that are more accessible and powerful, the development of multimodal AI that can process various data types, and the increasing use of AI in scientific research to address global challenges such as climate change, energy crises, and diseases. These trends are expected to make AI more integrated into everyday technologies and help solve some of the world’s most pressing problems.
Meta Platforms, the parent company of Facebook, Instagram, WhatsApp, and Oculus VR, is beginning a small trial in the U.S. of a new multimodal AI designed to run on its Ray Ban Meta smart glasses. The new AI, set to launch publicly in 2024, takes advantage of the glasses' camera to provide information about both user queries and the world around them. The glasses currently have a limited voice-controlled AI assistant, but the new multimodal version aims to intelligently respond to video and photography. The trial will be conducted through an early access program, and the glasses are priced at $299.
Google showcased its new multimodal AI model, Gemini, during Google I/O 2023 with a fake hands-on video. While Gemini has potential, the video misrepresented the actual user experience by using text prompts and providing context to make the AI model appear more capable than it actually is. Google defended the video, stating that it was meant to inspire developers, but critics argue for more transparency in product demonstrations.
OpenAI's ChatGPT now has a new feature called GPT-4V, which allows the AI chatbot to read and respond to image prompts. Users can upload images to the ChatGPT app and ask questions related to the image. The system uses reinforcement learning from human feedback to generate responses. While GPT-4V shows promise, there are still concerns about its accuracy and potential biases. Users have already started experimenting with the feature, using it for tasks like getting a second opinion on artwork, identifying obscure images, writing code, and interpreting diagrams. OpenAI is also investing in improving its Dall-E image generator and plans to integrate it into ChatGPT.
OpenAI has released upgrades to its ChatGPT chatbot, enabling it to interact with images and voices, marking a significant step towards OpenAI's vision of artificial general intelligence. The new ChatGPT-Plus includes voice chat powered by a text-to-speech model and the ability to discuss images using image generation models. This upgrade follows the introduction of DALL-E 3, OpenAI's advanced text-to-image generator. Microsoft, OpenAI's largest backer, is also integrating OpenAI's AI capabilities into its consumer products, aiming to lead the AI assistant race. OpenAI acknowledges the risks associated with powerful multimodal AI systems and is taking cautious steps towards responsible AI development.
Google Gemini, an upcoming artificial intelligence (AI) system developed by Google's DeepMind division, is expected to be a multimodal AI model that combines text, images, and other data types. It may utilize tools and APIs, including Google's new AI infrastructure called Pathways, to scale up training on diverse datasets. Gemini is anticipated to come in various sizes and capabilities, with potential abilities like reasoning, problem-solving, memory, and planning. Early results are promising, and it aims to be an advanced chatbot and universal personal assistant integrated into people's daily lives. Competitors like Meta are also reportedly working on their own language models to compete with OpenAI's GPT model.