The article explores the often overlooked but crucial role of embeddings in large language models (LLMs), discussing their inscrutability, how they encode semantic meaning, and techniques like LogitLens for interpretability, while highlighting the complexity and high-dimensional nature of embedding spaces.
A coalition of AI safety researchers proposes Chain of Thought (CoT) monitoring, which involves examining the natural language reasoning steps of large language models to detect misbehavior before actions are taken. While promising for transparency and safety, CoT monitoring faces challenges like models hiding reasoning, obfuscation, and architectural shifts. The authors call for dedicated research to improve CoT's effectiveness as part of a broader safety strategy, emphasizing urgency in developing these oversight tools to prevent harmful AI behavior.
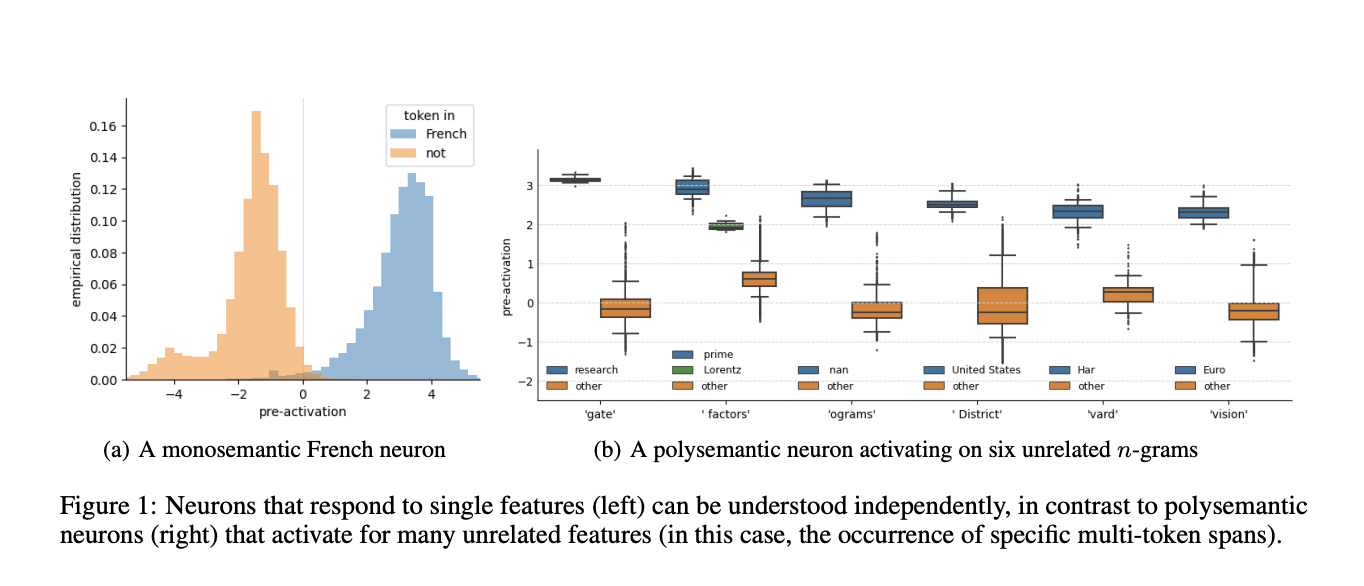
Researchers from MIT, Harvard, and Northeastern University have proposed a technique called sparse probing to better understand the neuronal activations of language models. By limiting the probing classifier to using a variable number of neurons, the method overcomes the limitations of prior probing methods and sheds light on the structure of language models. The researchers used state-of-the-art techniques to demonstrate the small-k optimality of the feature selection subproblem and found that the neurons of language models contain interpretable structures. However, caution must be exercised when drawing conclusions, and further analysis is needed. Sparse probing has benefits such as addressing the risk of conflating classification quality with ranking quality and allowing for the examination of how architectural choices affect polysemantic and superposition features. However, it also has limitations, including the need for secondary investigations of identified neurons and the inability to recognize features constructed across multiple layers. The researchers plan to build a repository of probing datasets to explore interpretability and encourage an empirical approach to AI research.
OpenAI's GPT-4 language model is being used to automatically generate and score explanations for neurons in the GPT-2 language model, in an effort to increase interpretability and understanding of AI systems. The process involves three stages: explanation generation, simulation using GPT-4, and comparison. While the current method is limited to simpler models, OpenAI hopes to improve the quality of interpretation with advances in machine learning technology. The dataset and source code are available on GitHub for further research.
The AI industry is desperate for regulation to slow down the competition and ensure safety. Priorities for regulation include interpretability, security, evaluations and audits, and liability for AI-design companies. The industry is willing to accept imperfect rules to ensure safety and prevent a race to the bottom.