"MIT, Harvard, and Northeastern University's 'Finding Neurons in a Haystack' Initiative Utilizes Sparse Probing"
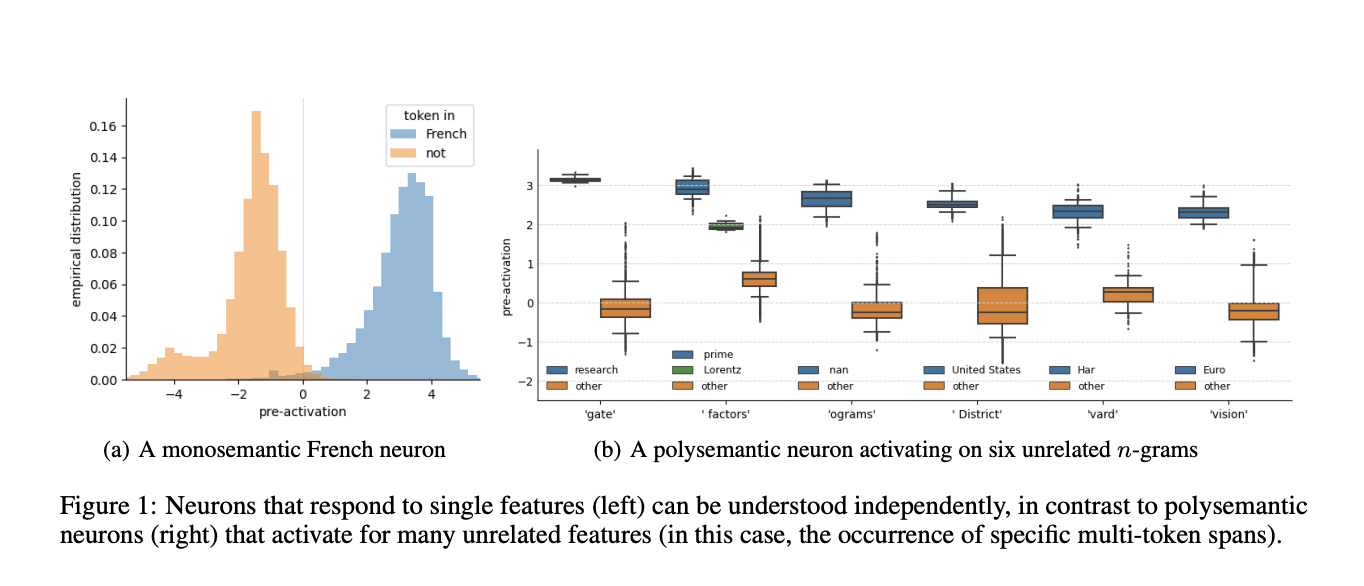
Researchers from MIT, Harvard, and Northeastern University have proposed a technique called sparse probing to better understand the neuronal activations of language models. By limiting the probing classifier to using a variable number of neurons, the method overcomes the limitations of prior probing methods and sheds light on the structure of language models. The researchers used state-of-the-art techniques to demonstrate the small-k optimality of the feature selection subproblem and found that the neurons of language models contain interpretable structures. However, caution must be exercised when drawing conclusions, and further analysis is needed. Sparse probing has benefits such as addressing the risk of conflating classification quality with ranking quality and allowing for the examination of how architectural choices affect polysemantic and superposition features. However, it also has limitations, including the need for secondary investigations of identified neurons and the inability to recognize features constructed across multiple layers. The researchers plan to build a repository of probing datasets to explore interpretability and encourage an empirical approach to AI research.
Reading Insights
0
1
4 min
vs 5 min read
82%
912 → 167 words
Want the full story? Read the original article
Read on MarkTechPost