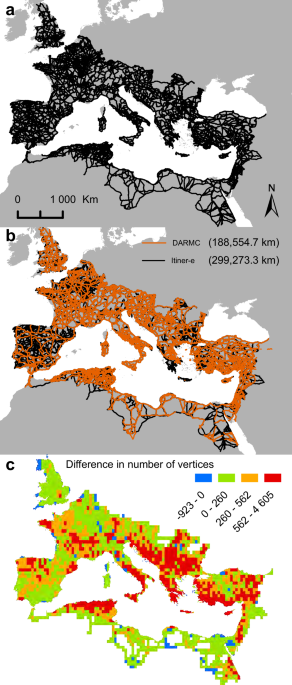
Itiner-e is a comprehensive, high-resolution digital dataset mapping nearly 300,000 km of Roman roads across the empire, created from archaeological, historical, and remote sensing sources, revealing significant gaps in certainty and coverage that can inform future research on ancient mobility and infrastructure development.
Harvard University, in collaboration with Google, plans to release a dataset of approximately 1 million public-domain books for AI training, sourced from Google's book-scanning project. This initiative, part of Harvard's Institutional Data Initiative (IDI), aims to democratize access to AI training data, with financial support from Microsoft and OpenAI. The dataset will include works from authors like Dickens and Shakespeare, and is intended to be accessible to research labs and AI startups.
The LAION-5B dataset, used to train popular AI image generators like Stable Diffusion, has been found to contain thousands of instances of child sexual abuse material (CSAM), according to a study by the Stanford Internet Observatory (SIO). The dataset includes metadata and URLs pointing to the images, some of which were found hosted on websites like Reddit, Twitter, and adult websites. The SIO reported the findings to the National Center for Missing and Exploited Children (NCMEC) and the Canadian Centre for Child Protection (C3P), and the removal of the identified source material is underway. LAION has announced plans for regular maintenance procedures to remove suspicious and potentially unlawful content from its datasets.
Stanford's Internet Observatory discovered that the popular AI image training dataset, LAION-5B, used by Stability AI and Google's Imagen image generators, contained links to child sexual abuse imagery. The dataset included at least 1,679 illegal images scraped from social media and adult websites. While the dataset does not store the images itself, it provides links and alt text. LAION, the nonprofit managing the dataset, temporarily removed it, emphasizing a "zero-tolerance" policy for harmful content. Stanford researchers recommended deprecating and ceasing distribution of models trained on LAION-5B, and US attorneys general have called for an investigation into the impact of AI on child exploitation and the prohibition of AI-generated child sexual abuse material.
Google's DeepMind robotics team has collaborated with 33 research institutes to create Open X-Embodiment, a shared database aimed at advancing robotics through the use of a large, diverse dataset. Similar to ImageNet for computer vision, Open X-Embodiment features over 500 skills and 150,000 tasks from 22 different robot types. The database is being made available to the research community to reduce barriers and accelerate research in robot learning, with the goal of enabling robots to learn from each other and researchers to learn from one another.
The Washington Post has created a search tool that allows users to find out if their website or content was used to train AI systems as part of Google's C4 dataset, which includes websites and content creators that generative AI could potentially negatively impact. The C4 dataset is only part of the data used by Google Bard and other large language models, which also use Wikipedia, Reddit, and other sources. Reddit has updated its API terms and will now charge some companies, including Google and OpenAI, for access to its valuable corpus of data.
Meta has released an artificial intelligence model called Segment Anything Model (SAM) that can identify individual objects within images and videos, even if it has not encountered them before. SAM can select objects by clicking on them or writing text prompts. Meta has also released a dataset of image annotations, which it claims is the largest of its kind. The SAM model and dataset will be available for download under a non-commercial license.
Meta has released an AI model called "Segment Anything" that can detect objects in pictures and videos even if they weren't part of the training set. The model can work in tandem with other models and can limit the need for additional AI training. The AI model and dataset will be downloadable with a non-commercial license. While the model is flawed, it may help in situations where it's impractical to rely exclusively on training data.
Meta has introduced an AI model called the Segment Anything Model (SAM) that can identify individual objects in images and videos, even those not encountered during training. SAM is an image segmentation model that can respond to text prompts or user clicks to isolate specific objects within an image. Meta hopes to "democratize" the process of creating accurate segmentation models by reducing the need for specialized training and expertise. Meta has also assembled a dataset it calls "SA-1B" that includes 11 million images licensed from "a large photo company" and 1.1 billion segmentation masks produced by its segmentation model.