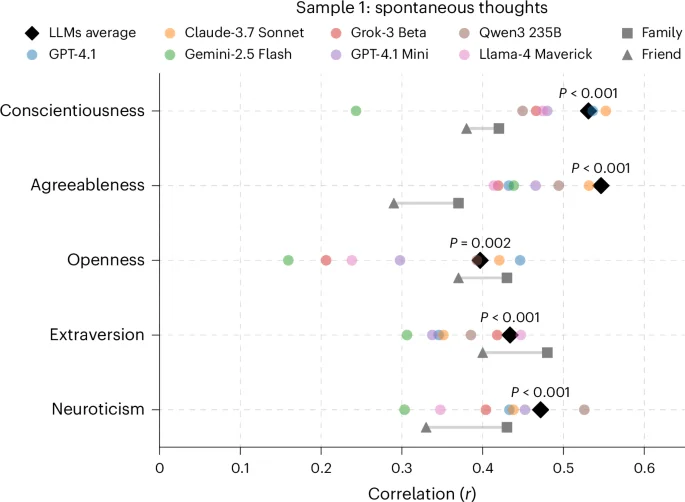
AI coach sharpens peer review with clearer, more constructive feedback
A five-LLM AI coach, called Review Feedback Agent, was developed to help peer reviewers deliver more specific, constructive, and less toxic feedback. When tested on thousands of existing reviews, it frequently suggested actionable ways to improve comments. It remains unclear whether this improves the quality or impact of the papers being reviewed, requiring further study.