Debunking the Myth of Scary AI Emergent Abilities: Insights from Stanford and John Hopkins Studies
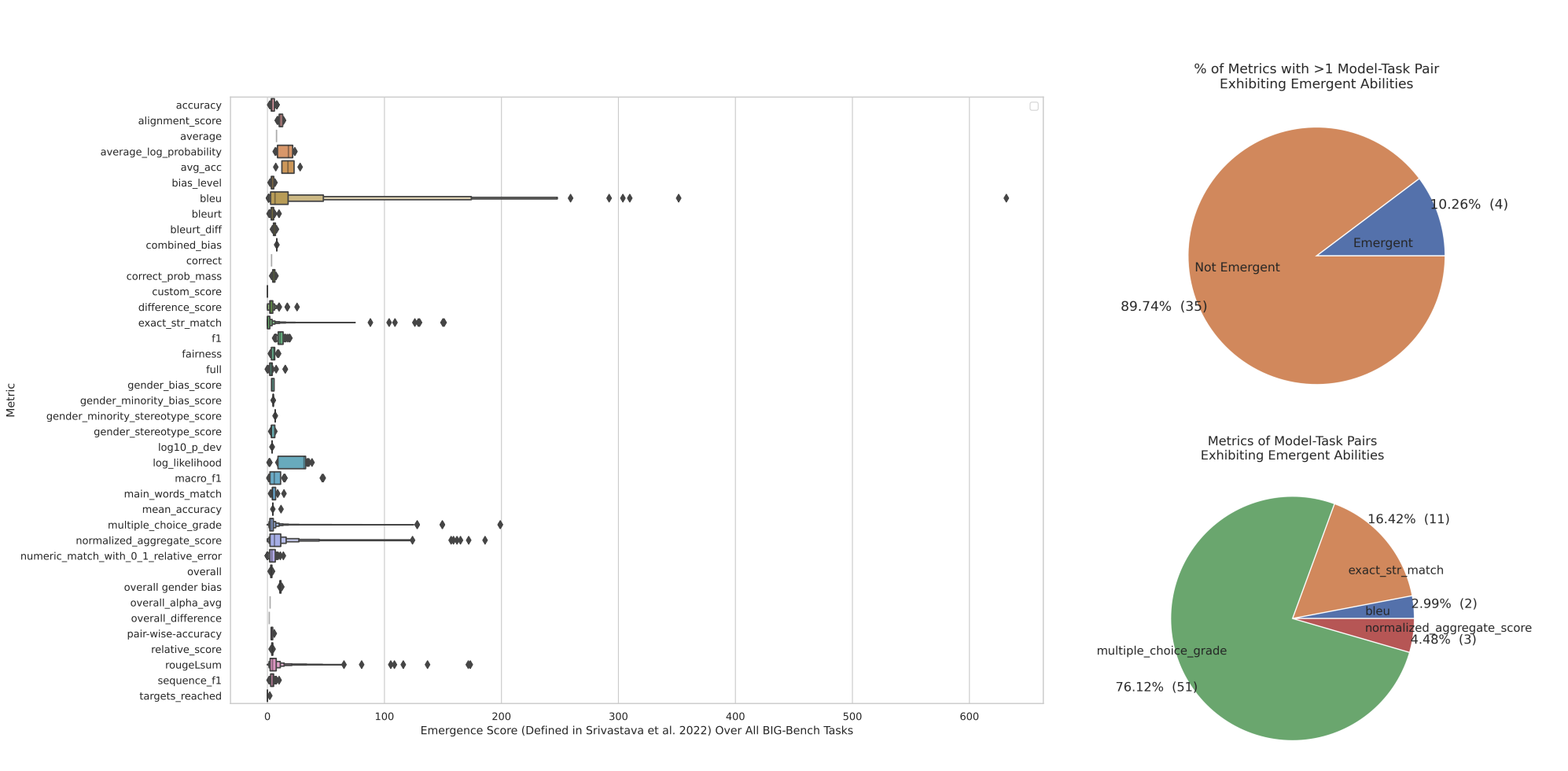
Researchers from Stanford present an alternative explanation for the seemingly sharp and unpredictable emergent abilities of large language models (LLMs). They argue that the researcher's choice of a metric that nonlinearly or discontinuously deforms per-token error rates, the lack of test data to accurately estimate the performance of smaller models, and the evaluation of too few large-scale models are all causes of emergent abilities being a mirage. They provide a mathematical model to express their alternate viewpoint and show how it statistically supports the evidence for emergent LLM skills. They put their alternate theory to the test in three complementary ways and demonstrate that emergent skills only occur for certain metrics and not for model families on tasks.
- A New AI Research From Stanford Presents an Alternative Explanation for Seemingly Sharp and Unpredictable Emergent Abilities of Large Language Models MarkTechPost
- Scary 'Emergent' AI Abilities Are Just a 'Mirage' Produced by Researchers, Stanford Study Says VICE
- A New AI Research from John Hopkins Explains How AI Can Perform Better at Theory of Mind Tests than Actual Humans MarkTechPost
- View Full Coverage on Google News
Reading Insights
0
3
4 min
vs 5 min read
86%
832 → 118 words
Want the full story? Read the original article
Read on MarkTechPost