Google's TurboQuant Slashes LLM Memory 6x Without Sacrificing Output
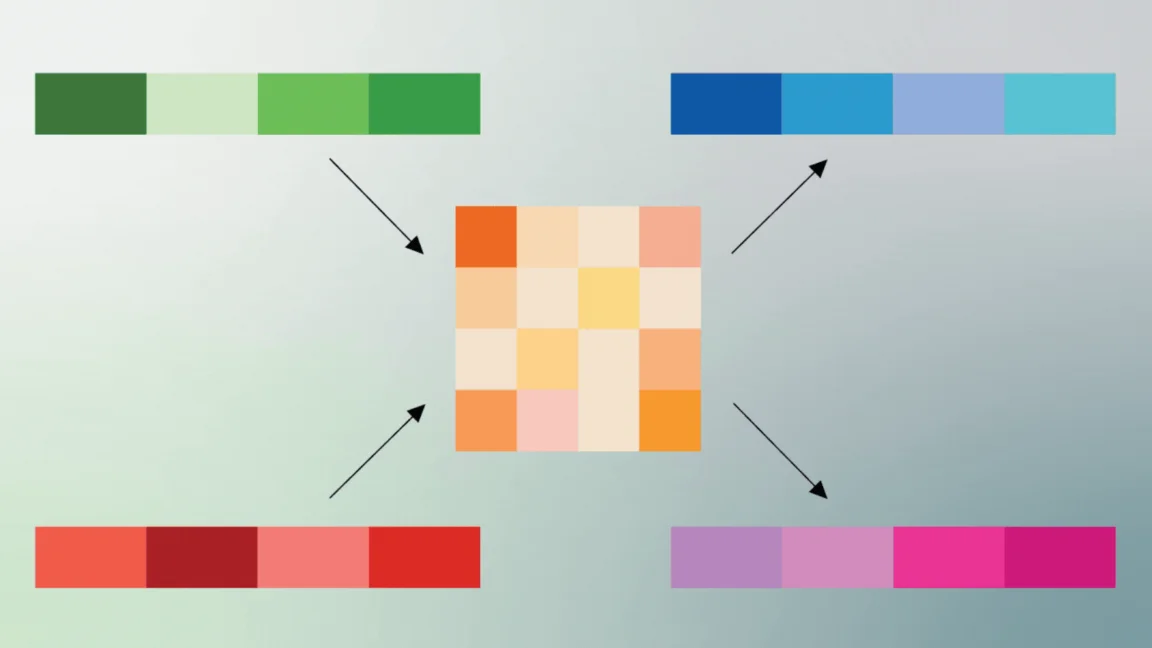
Google Research's TurboQuant uses PolarQuant and Quantized Johnson-Lindenstrauss (QJL) to compress the LLM key-value cache, quantizing to as little as 3 bits with no retraining and delivering up to 6x memory reduction and up to 8x faster attention logits at 4-bit, with perfect downstream results in tests on Gemma and Mistral.